


VToonify: An innovative AI model for generating real-time artistic portrait videos.
In Brief
A novel framework called VToonify has been crafted by developers to enable controlled and high-resolution portrait video style transformations.
The framework utilizes the mid- and high-resolution layers of StyleGAN to produce visually striking artistic portraits.
This system allows for the enhancement of existing models based on StyleGAN. image toonification models to video.
Scholars at Nanyang Technological University have unveiled an exciting new VToonify framework. This innovative approach is aimed at generating high-resolution, controllable portrait video style transfers. By taking advantage of StyleGAN's mid- and high-resolution layers, VToonify successfully produces artistic portraits while maintaining important frame details through the extraction of multi-scale content features via an encoder. Results from various experiments indicate that this framework consistently outputs high-quality videos while accurately rendering desired facial expressions, all without needing face alignment or being restricted by frame sizes. [SIGGRAPH Asia 2022] VToonify: Offering controllable high-resolution transfers for portrait video styles.
VToonify: A real-time artificial intelligence tool for crafting artistic portrait videos.

OpenAI is developing a new artificial intelligence model aimed specifically at video generation. GitHub for more details.
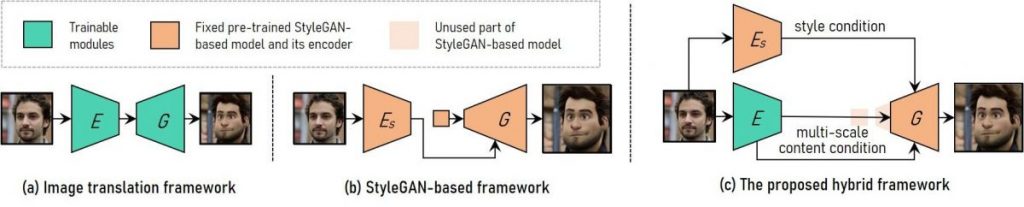
(A) The image translation framework employs fully convolutional networks to accommodate varying input sizes. However, teaching high-resolution and controlled styles from the ground up remains a challenge.
(B) Meanwhile, the StyleGAN-based framework, which only accommodates fixed image sizes and can result in detail loss, utilizes a pre-trained model for its high-resolution and controllable style transfers.
(C) To create a fully convolutional architecture that mirrors the image translation framework's design, our hybrid approach modifies StyleGAN by removing its limitations concerning fixed-sized input features and low-resolution layers.
To ensure that frame details are preserved, developers have trained an encoder that captures multi-scale content features from the input frames as an additional condition for content.
VToonify leverages the style control capacity offered by the StyleGAN model by integrating it within its generator to refine both the data and the model.
| Related article: Lambda Labs has introduced a new AI image mixer capable of blending up to five different images together. |
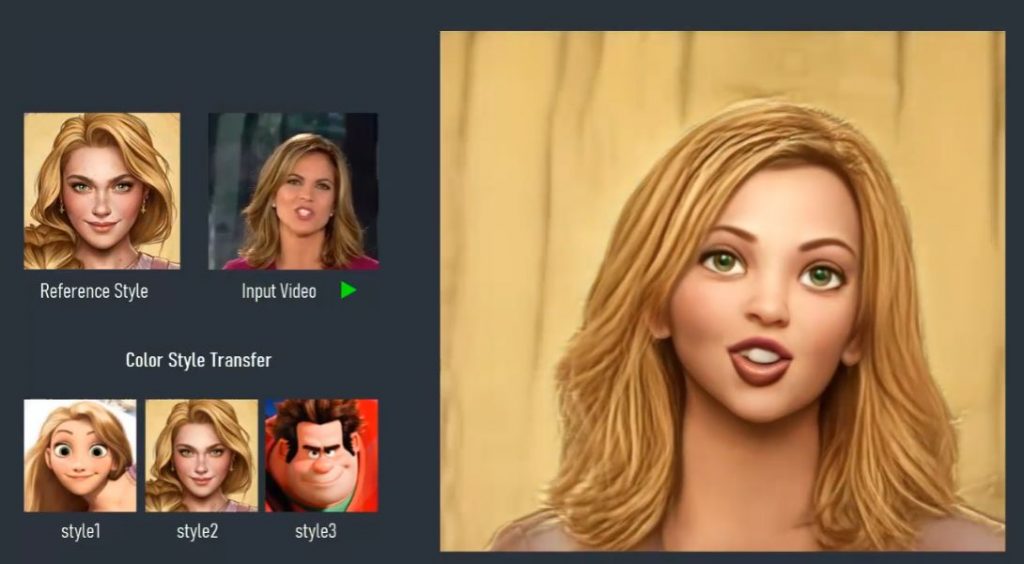
VToonify inherits desirable characteristics from existing StyleGAN-based toonification models, thereby enhancing them for video applications. video Our VToonify, based on the DualStyleGAN framework, offers the following features:
- Exemplar-based style transfer;
- Modification of style degree;
- Exemplar-based color style transfer.

Read more about AI:
Disclaimer
In line with the Trust Project guidelines Please be aware that the information on this page is not intended to serve as, nor should it be perceived as, legal, tax, investment, financial, or any other advice. It is crucial to only invest what you can afford to lose and to seek independent financial counsel if you have any uncertainties. For additional insights, we recommend checking the provided terms and conditions as well as the help and support sections from the issuer or advertiser. MetaversePost is dedicated to delivering precise and impartial reports; however, market conditions may evolve without prior warning.




