


VideoDirectorGPT: The Intelligent Director That Is Changing the Game in Text-to-Video Creation

Converting written prompts into well-structured visual narratives presents a key challenge in text-to-video generation, where numerous emerging models are making their mark. Unlike traditional filmmaking, this task requires a distinct skill set akin to direction, and mastering Video Object Generation (VOG) is no small feat. Furthermore, the ability to observe keenly is an art in itself.
To tackle this, VideoDirectorGPT introduces a fresh perspective, designed to create precise and cohesive multi-scene videos, simplifying the entire process. Essentially, it utilizes a two-step methodology that combines the capabilities of Large Language Models (LLMs) with the technique of video scheduling.
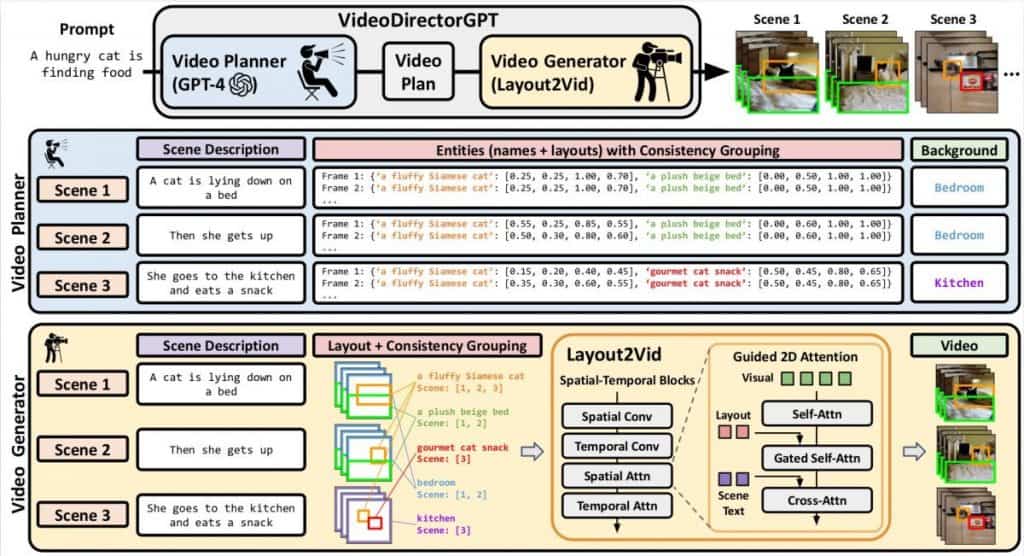
LLM-Guided Scheduling
In the initial phase, VideoDirectorGPT leverages LLMs as video schedulers, where the LLM takes on the role of a narrative architect, formulating the central storyline for the multi-scene video. This narrative includes specific scene descriptions, comprehensive lists of objects and backgrounds, detailed layouts of objects on a frame-by-frame basis that include bounding boxes, as well as logically grouped objects and backgrounds for clarity.
Layout2Vid Video Generation
Once the LLM has carefully devised the video framework, the next step is to bring the concept to life. This is where Layout2Vid, the module responsible for video generation, steps in. Building on the groundwork laid in the previous phase, Layout2Vid utilizes matching image and text embeddings to represent objects and backgrounds as outlined in the video plan.
What sets this apart is its ability to manipulate the placement of objects through a sophisticated 2D attention mechanism that is integrated within the spatial attention unit.
Yandex has rolled out an innovative feature known as Masterpiece, allowing users to craft short videos up to 4 seconds in duration with a refresh rate of 24 frames per second. This technology employs a cascaded diffusion technique to generate subsequent video frames, producing imagery that resonates with the user's specified narrative. Masterpiece stands out for its user-friendliness, making it an appealing choice for beginners as well as seasoned creators. Its broader implications suggest potential transformations in the ways digital content is created and consumed. generated content With enhancements, the text-to-video model can now generate entirely new videos from the ground up using a text prompt, representing a significant leap forward compared to its predecessor. This advancement not only conserves time and effort but also allows for the production of videos without requiring extensive editing expertise. Moreover, the Gen-2 model can take an uploaded image and convert it into a high-quality short video clip, surpassing competitors in this area. This technology promises to facilitate the creation and sharing of content across social media platforms, which could greatly benefit sites like Facebook and TikTok.
In August, Top 50 Text-to-Video AI Prompts: Simple Image Animation 10+ Exceptional Text-to-Video AI Generators: Powerful and Free Options
Also, earlier this year, Runway released Gen-2 Please be aware that the information shared on this page should not be considered legal, tax, investment, financial, or any other kind of advice. Always invest only what you can afford to lose and seek independent financial guidance if you have any uncertainties. For more details, we recommend reviewing the terms and conditions as well as the help resources provided by the issuer or advertiser. MetaversePost is dedicated to providing accurate, unbiased information, but please note that market conditions can change without prior notice.
Read more related topics:
Disclaimer
In line with the Trust Project guidelines Addressing DeFi Fragmentation: How Omniston Enhances Liquidity on TON




