


Exploring the Top 30+ Transformer Models in AI: Their Functions and Mechanisms
Over the past few months, a variety of Transformer models have made their debut in the AI landscape, each equipped with its own unique and often entertaining designations. Nevertheless, these names often fall short in explaining the actual capabilities of the models. This article intends to deliver a thorough and user-friendly rundown of the most prominent Transformer models. It will categorize these models while also shedding light on key developments and innovations within the Transformer ecosystem. The highlight reel will explore models trained through self-supervised methods, akin to BERT and GPT-3, alongside models that receive extra training with human input, like the InstructGPT that powers ChatGPT.

| Pro Tips |
|---|
| This guide is crafted to equip individuals with thorough knowledge and hands-on abilities in prompt engineering, catering to everyone from novices to seasoned experts. |
| There are many courses accessible for those eager to dive deeper into AI and the associated technologies. |
| Take a look at the top 10+ AI accelerators predicted to lead the market in terms of efficiency and effectiveness. |
- What are Transformers in AI?
- What are Encoders and Decoders in AI?
- What are Attention Layers in AI?
- What are Fine-tuned Models in AI?
- What makes Transformers the front-runners in the AI landscape?
- 3 Types of Pretraining Architectures
- 8 Categories of Tasks for Pre-trained Models
- Top 30+ Transformers in AI
- FAQs
What are Transformers in AI?
Transformers represent a category of deep learning models first unveiled in a research manuscript by Google scholars titled “ Attention is All you Need ” back in 2017. This groundbreaking paper has garnered massive acclaim, racking up over 38,000 citations in a mere five years.
The pioneering Transformer architecture stands as a particular variant of encoder-decoder models that enjoyed popularity prior to its introduction. These frameworks largely depended on LSTM and diverse types of Recurrent Neural Networks ( RNNs ), with mechanisms like attention being just a part of the bigger picture. The Transformer manuscript introduced a groundbreaking concept: the notion that attention could operate as the exclusive mechanism to forge connections between input and output.
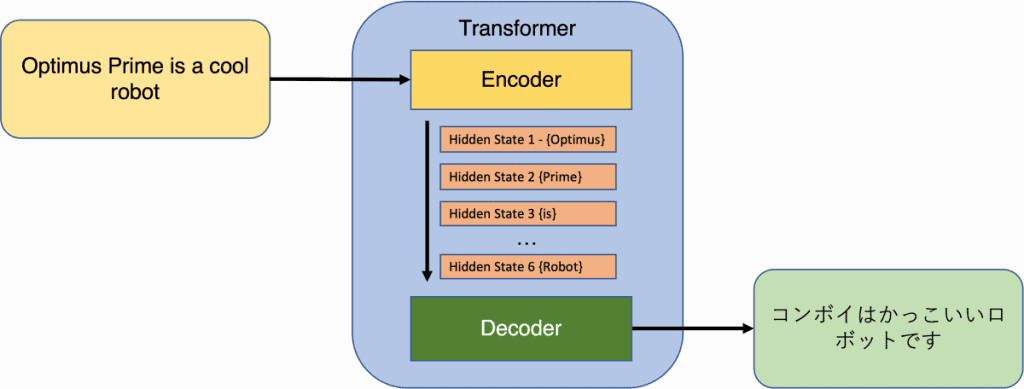
In Transformers, the inputs comprise a sequence of tokens, which could encompass words or subwords in natural language processing ( NLP ). Subwords are frequently utilized in NLP systems to mitigate the problem of encountering out-of-vocabulary terms. The encoder outputs a fixed-dimensional representation for each token, supplemented by a separate embedding that captures the essence of the whole sequence. The decoder then processes the encoder’s output to generate a series of tokens for its output.
Since the original Transformer paper was released, well-known models such as BERT and GPT have integrated elements from the foundational architecture, whether by leveraging the encoder or decoder configurations. What ties these models together is their layered structure that incorporates self-attention layers coupled with feed-forward networks. In Transformers, each token in the input navigates its own journey through the layers, maintaining direct relationships with each of the other tokens within the input sequence. This distinctive attribute enables parallel and efficient computation of token representations, a feat that traditional sequential models like RNNs struggle to achieve.
While this review merely scratches the surface of the Transformer design, it offers an overview of its critical components. For a more in-depth exploration, we recommend checking out the original research paper or The Illustrated Transformer article.
What are Encoders and Decoders in AI?
Picture two models: one acts as an encoder and the other as a decoder, working together similar to a coordinated team effort. The encoder converts an input into a fixed-length vector, which the decoder subsequently transforms into an output sequence. Both models train in unison to ensure the output aligns closely with the input.
Each of the encoder and decoder is composed of multiple layers. In the encoder, every layer contains two key sub-layers: a multi-head self-attention layer and a straightforward feed-forward network. The self-attention component enables each token in the input to decipher its relationships with all other tokens. These sublayers are also equipped with residual connections and normalization techniques to streamline the learning process.
The decoder’s multi-head self-attention layer operates somewhat differently from the encoder. It conceals the tokens located to the right of the focused token, ensuring the decoder considers only the tokens preceding the one it's attempting to predict. This masked multi-head attention fortifies the decoder's predictive capacity. Moreover, the decoder incorporates an additional sublayer, which is a multi-head attention layer tasked with focusing on all the encoder's outputs.
It's essential to acknowledge that various modifications have been made to these intricate details across different Transformer model types. Models like BERT and GPT , for instance, are variations centered on either the encoder or decoder dimensions of the original design.
What are Attention Layers in AI?
In the architecture we delved into earlier, the multi-head attention layers are the special sauce that elevates its capabilities. But what exactly is attention? Envision it as a mechanism that links a query to a body of information and produces an output. Every token in the input has a corresponding query, key, and value assigned to it. The output representation for each token is calculated as a weighted sum of the values, where the weight is determined by how closely the value aligns with the query.
Transformers implement a compatibility function known as scaled dot product to derive these weights. A fascinating aspect of attention in Transformers is that each token undergoes an individualized computational pathway, enabling simultaneous processing of every token within the input sequence. It consists of several independent attention blocks that produce representations for each token, which are then amalgamated to form the token’s ultimate representation.
In comparison to other network types such as recurrent and convolutional networks , attention layers possess distinct advantages. They are computationally efficient, which allows for rapid processing of information. Their higher connectivity also plays a significant role when capturing long-term dependencies within sequences.
What are Fine-tuned Models in AI?
Foundation models are robust models trained on extensive datasets. They can be refined or adapted for specific tasks by training them on a smaller, focused dataset, a trend that has solidified the dominance of Transformer-based models in language-centric machine learning endeavours. target-specific data . This approach, popularized by the BERT paper For models like BERT, they yield representations of input tokens but don't execute tasks independently. To enhance their utility, supplementary
are layered atop, allowing the model to undergo end-to-end training, a method referred to as fine-tuning. In contrast, with models like neural layers such as GPT, the strategy diverges slightly. GPT functions as a decoder-based language model specifically trained to anticipate the subsequent word in a phrase. Through extensive training on massive online datasets, GPT generates reasonably coherent outputs grounded in input queries or prompts. generative models To augment GPT's utility, OpenAI’s team developed
, which is fine-tuned to adhere to human directives. This is achieved by training GPT with data labeled by humans across various tasks. InstructGPT holds the capability to carry out diverse tasks, functioning as a backbone for widely-used applications like ChatGPT. InstructGPT Fine-tuning is also a useful approach for crafting versions of foundational models that are tailored for specific tasks
beyond simple language tasks. For instance, there exist models that are optimized for semantically related tasks, such as text classification and search retrieval. Furthermore, transformer encoders have shown success when fine-tuned for multi-task specific purposes to execute multiple semantic functions within a single unified model. learning frameworks Nowadays, fine-tuning is pivotal in developing versions of foundational models that cater to a broad user base. The methodology entails creating responses to input
prompts, followed by human assessments of the results. Reinforcement learning infused with human feedback . This ranking is used to train a reward model , which assigns scores to each output. is then utilized to further enhance the model's training. Transformers, which emerged as robust models in the sphere of language translation, quickly revealed their versatility for a myriad of language-related tasks through training on expansive datasets of unlabeled text, followed by fine-tuning on smaller labeled sets. This dual-phase strategy enabled Transformers to internalize a substantial grasp of linguistic fundamentals.
What makes Transformers the front-runners in the AI landscape?
Initially developed for language-based tasks, the Transformer architecture has found applications across various domains such as
, audio, music, and even human actions. This adaptability has rendered Transformers integral to the Generative AI sector, actively altering various societal elements. generating images The introduction of tools and frameworks like
has been instrumental in the extensive uptake of Transformer models. Companies such as Huggingface have been pioneering their PyTorch and TensorFlow for commercializing open-source Transformer libraries, while specialized hardware like NVIDIA’s Hopper Tensor Cores has notably accelerated both the training and inference speeds of these models. business around the idea A standout instance of Transformer application is ChatGPT,
. Its meteoric rise to popularity saw it attract millions of users in no time. Additionally, OpenAI has announced the advent of GPT-4, a more potent iteration capable of achieving human-like performance across tasks such as a chatbot released by OpenAI The influence of Transformers within the AI arena and their broad spectrum of applications is irrefutable. They have medical and legal exams .
transformed our approach to language-related tasks and are laying the groundwork for groundbreaking progress in generative AI. transformed the way The original Transformer architecture, consisting of an Encoder and a Decoder, has undergone various adaptations geared towards addressing specific requirements. Let’s simplify these adaptations for better comprehension.
3 Types of Pretraining Architectures
Encoder Pretraining : These models prioritize grasping complete sentences or paragraphs. During the pretraining phase, the encoder is tasked with reconstructing masked tokens from the input phrases. This approach aids the model in comprehending the overarching context. Such models excel in tasks like text classification, entailment, and extractive question answering.
- A Comprehensive Overview of 30+ Transformer Models in AI: Their Functions and Mechanisms - Metaverse Post
- Recently, a variety of Transformer models featuring distinctive and sometimes quirky titles have surfaced in the AI landscape. Yet, these monikers might not shed light on the functionalities these models offer.
- A Detailed Exploration of 30+ Transformer Models in AI: Their Functions and Mechanisms
FTC’s Attempt to Halt Microsoft and Activision Merger Denied
8 Categories of Tasks for Pre-trained Models
Published: June 12, 2023, at 6:52 am. Updated: June 12, 2023, at 6:52 am
- To enhance your experience with local languages, we occasionally utilize an auto-translation tool. Keep in mind that the translations may not always be precise, so it’s advisable to proceed with caution.
- In the past few months, many Transformer models have made their appearance within the AI community, each boasting interesting names that might not accurately reflect their operational capabilities. This article seeks to curate a thorough and accessible list of the leading Transformer models, categorize them, and highlight key innovations within this architectural family. The comprehensive overview will encompass
- through techniques like self-supervised learning, seen in models such as BERT and GPT-3, along with those undergoing additional human-assisted training processes, like the InstructGPT model utilized by ChatGPT.
- is aimed at equipping learners, from novices to advanced users, with the essential expertise and practical know-how in prompt engineering.
- offered for individuals interested in expanding their knowledge regarding AI and associated technologies.
- which are anticipated to dominate the market with superior performance.
- What makes Transformers the frontrunners in the AI arena?
- 8 Categories of Tasks Suitable for Pre-trained Models
Transformers represent a category of deep learning architectures that debuted in a groundbreaking research article titled “
Top 30+ Transformers in AI
| Name | Pretraining Architecture | Task | Application | Developed by |
|---|---|---|---|---|
| ALBERT | Encoder | MLM/NSP | Same as BERT | |
| Alpaca | Decoder | LM | ” authored by Google scientists in 2017. This publication has achieved staggering fame, racking up over 38,000 citations within just five years. | Stanford |
| LSTM | RNNs | What are Transformers in AI? | Credit: dominodatalab.com | NLP |
| BERT | What are Encoders and Decoders in AI? | working together | The foundational Transformer model is a specialized type of encoder-decoder architecture that had seen considerable traction prior to its introduction. These models primarily hinged on | The decoder’s multi-head |
| self-attention layer | Models like BERT and GPT | What are Attention Layers in AI? | and other iterations of Recurrent Neural Networks (RNNs), with attention being just one method amongst others. However, the Transformer paper put forth a groundbreaking hypothesis that attention could function as the sole mechanism for establishing relationships between input and output. | convolutional networks |
| What are Fine-tuned Models in AI? | Foundation models | target-specific data | Within the realm of Transformers, the input consists of a series of tokens, which could be words or subwords during natural language processing (NLP). Subwords are frequently utilized in NLP models to tackle the issue of encountering out-of-vocabulary terms. The encoder’s output produces a fixed-dimensional representation for each token while also generating a dedicated embedding for the entire sequence. Meanwhile, the decoder processes the encoder’s output to produce a new sequence of tokens. | . This approach, popularized by the |
| BERT paper | neural layers | generative models | and other iterations of Recurrent Neural Networks (RNNs), with attention being just one method amongst others. However, the Transformer paper put forth a groundbreaking hypothesis that attention could function as the sole mechanism for establishing relationships between input and output. | InstructGPT |
| specific purposes | learning frameworks | . This ranking is used to train a | and other iterations of Recurrent Neural Networks (RNNs), with attention being just one method amongst others. However, the Transformer paper put forth a groundbreaking hypothesis that attention could function as the sole mechanism for establishing relationships between input and output. | reward model |
| , which assigns scores to each output. | generating images | PyTorch | and | TensorFlow |
| business around the idea | a chatbot released by OpenAI | medical and legal exams | and other iterations of Recurrent Neural Networks (RNNs), with attention being just one method amongst others. However, the Transformer paper put forth a groundbreaking hypothesis that attention could function as the sole mechanism for establishing relationships between input and output. | transformed the way |
| 3 Types of Pretraining Architectures | Top 30+ Transformers in AI | Name | Pretraining Architecture | |
| Task | Application | Developed by | ALBERT | |
| Encoder | MLM/NSP | Same as BERT | Alpaca | |
| Decoder | LM | Stanford | LSTM | RNNs |
| What are Transformers in AI? | Credit: dominodatalab.com | NLP | BERT | What are Encoders and Decoders in AI? |
| working together | The decoder’s multi-head | self-attention layer | Since the inception of the Transformer paper, renowned models such as | Models like BERT and GPT |
| What are Attention Layers in AI? | convolutional networks | What are Fine-tuned Models in AI? | Foundation models | target-specific data |
| . This approach, popularized by the | BERT paper | neural layers | Within the realm of Transformers, the input consists of a series of tokens, which could be words or subwords during natural language processing (NLP). Subwords are frequently utilized in NLP models to tackle the issue of encountering out-of-vocabulary terms. The encoder’s output produces a fixed-dimensional representation for each token while also generating a dedicated embedding for the entire sequence. Meanwhile, the decoder processes the encoder’s output to produce a new sequence of tokens. | generative models |
| InstructGPT | specific purposes | learning frameworks | . This ranking is used to train a | reward model |
| , which assigns scores to each output. | generating images | PyTorch | ” authored by Google scientists in 2017. This publication has achieved staggering fame, racking up over 38,000 citations within just five years. | and |
| TensorFlow | business around the idea | a chatbot released by OpenAI | medical and legal exams | transformed the way |
| 3 Types of Pretraining Architectures | Top 30+ Transformers in AI | Name | Pretraining Architecture | Task |
| Application | Developed by | ALBERT | and GPT have integrated components from the original architecture, utilizing either the encoder or decoder structures. A notable trait these models share is their layer architecture, which incorporates self-attention mechanisms along with feed-forward components. In Transformers, each input token follows an individual path through the layers while maintaining direct connections with every other token in the input stream. This distinct quality facilitates parallel and efficient computation of contextual representations for tokens, a capability that traditional sequential models like RNNs struggle to achieve. | Encoder |
| MLM/NSP | Same as BERT | Alpaca | Decoder | |
| LM | Stanford | AlphaFold | Encoder | Protein folding prediction |
| Protein folding | Deepmind | Anthropic Assistant (see also) | While this article merely grazes the surface of the Transformer model's architecture, it offers a peek into its core elements. For a deeper dive, we suggest looking at the original research paper or the Illustrated Transformer post. | Decoder |
| LM | Anthropic | BART | Envision having two models—an encoder and a decoder, | Encoder/Decoder |
| DAE | BERT | Encoder | MLM/NSP | |
| BlenderBot 3 | Decoder | LM | ||
| BLOOM | Decoder | LM | that function like a team. The encoder converts the input into a fixed-length vector, after which the decoder transforms this vector into a sequence of outputs. These models are trained in conjunction to ensure that the output aligns closely with the input. | Big Science/Huggingface |
| ChatGPT | Decoder | LM | Dialog agents | OpenAI |
| Chinchilla | Decoder | LM | Both the encoder and decoder consist of multiple layers. Each layer in the encoder is composed of two sub-layers: a multi-head self-attention layer and a basic feed-forward network. The self-attention layer aids each token in the input to comprehend the relationships it has with all other tokens. These sub-layers also include a residual connection and layer normalization to facilitate a smoother learning experience. | Deepmind |
| CLIP | Encoder | Image/Object classification | Within the realm of Transformers, the input consists of a series of tokens, which could be words or subwords during natural language processing (NLP). Subwords are frequently utilized in NLP models to tackle the issue of encountering out-of-vocabulary terms. The encoder’s output produces a fixed-dimensional representation for each token while also generating a dedicated embedding for the entire sequence. Meanwhile, the decoder processes the encoder’s output to produce a new sequence of tokens. | OpenAI |
| CTRL | Decoder | Controllable text generation | operates differently from the encoder's attention mechanism. It applies a mask to the tokens on the right side of the focal token. This ensures the decoder only references the preceding tokens when predicting the current token. This masked multi-head attention is crucial for the decoder in crafting precise predictions. Furthermore, the decoder features an additional sub-layer dedicated to multi-head attention over all encoder outputs. | Salesforce |
| DALL-E | Decoder | Caption prediction | Text to image | OpenAI |
| DALL-E-2 | Encoder/Decoder | Caption prediction | Text to image | Do keep in mind that these specific components have been adjusted in various Transformer model variants. |
OpenAI
DeBERTa Decoder for instance, are grounded in either the encoder or decoder aspects of the initial architecture.
In the discussed model architecture, multi-head attention layers are the pivotal components that enhance its capabilities. But what does attention really entail? Visualize it as a function that links a question to relevant data inputs, producing an output. Each input token is associated with a query, key, and value. The output representation of each token is computed as a weighted sum of the values, where the weight assigned to each value hinges on its alignment with the query.
Transformers leverage a compatibility function known as scaled dot product to derive these weights. A striking feature of attention in Transformers is that every token engages in its independent calculation, allowing for parallel processing of all tokens in the input stream. Essentially, several attention blocks work autonomously to derive representations for each token, which are then aggregated to form the final representation. MLM In contrast to other network architectures like recurrent and
attention layers come with advantages. They are computationally efficient, providing rapid information processing. Their expanded connectivity is beneficial for capturing long-range relationships in sequences.
are robust models trained on extensive general datasets. They can then be fine-tuned for specific tasks by conducting additional training on limited task-specific data sets, which has led to the prevailing success of Transformer-based models in language-centric machine learning undertakings.
For instance, models like BERT yield representations for input tokens, but they don’t execute dedicated tasks autonomously. To enhance their utility, supplementary
Same as BERT
Amazon
Dolly Decoder , specifically tailored to adhere to human directives. This was accomplished by fine-tuning GPT with human-annotated datasets across various tasks. InstructGPT boasts the capability to handle a broad array of tasks and is employed by notable applications like ChatGPT.