


Introducing MiniGPT-4, the cutting-edge AI model designed for intricate image descriptions.
In Brief
MiniGPT-4 represents an AI framework that unifies visual comprehension with linguistic prowess. .
This model utilizes a static visual encoder known as Vicuna, in conjunction with GPT-4, the latest and most sophisticated language model developed by OpenAI.
MiniGPT-4 excels in crafting precise descriptions of images, generating narratives inspired by visuals, solving challenges depicted in pictures, and even instructing users on activities based on photographs.

Having a grasp of how to analyze and articulate visual information is vital for numerous applications, spanning from online retail to social media. Enter MiniGPT-4 , the most recent AI model that merges advanced visual interpretation with state-of-the-art language proficiency.
MiniGPT-4 utilizes a static visual encoder along with an expansive language model, integrated via a unified projection layer, allowing it to produce precise image descriptions, craft narratives and poems inspired by visuals, tackle depicted challenges, and even offer cooking advice based on images of food.
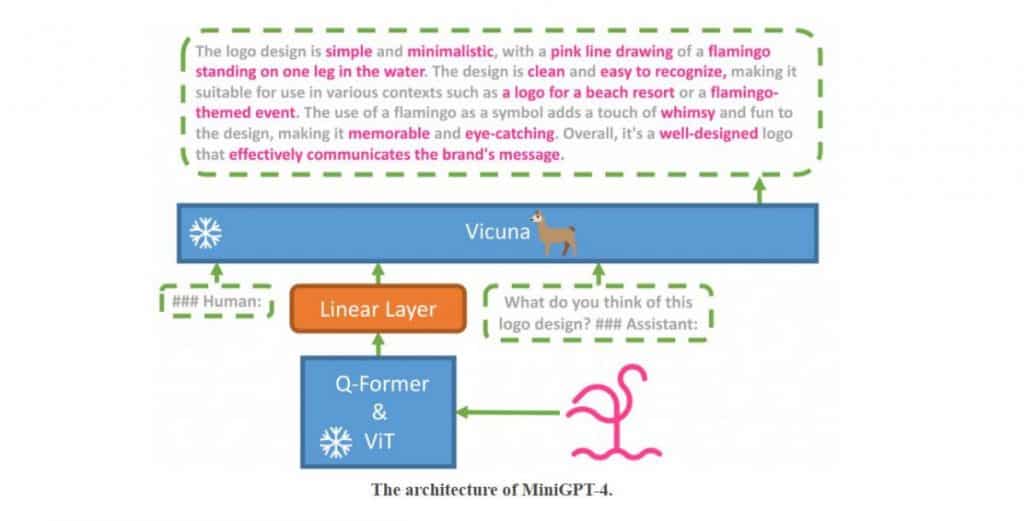
This model is remarkably proficient, needing the alignment of merely 5 million image-text pairings to train the linear layer that synchronizes visual elements with the frozen large language model, Vicuna.
Vicuna builds upon the foundation laid by LLaMA and is capable of managing intricate linguistic assignments. GPT-4 , the latest Large Language Model from OpenAI , empowers MiniGPT-4. The multimodal characteristic of GPT-4 distinguishes it from earlier versions, rendering it fitting for a variety of uses including gaming. Chrome extensions , and complex reasoning questions.
MiniGPT-4 exhibits capabilities akin to GPT-4, such as producing detailed descriptions of images and translating handwritten notes into web designs. In efforts to refine the model's language production, a superior dataset has been curated for additional fine-tuning using a conversational format, resulting in enhanced language generation that boasts greater reliability and overall efficiency.
The model's remarkable abilities derive from its two-stage training process , granting MiniGPT the capability to produce accurate and fluid language explanations of visual content. In the initial phase, MiniGPT-4 is trained on a multitude of image-text pairs, enabling it to learn about various subjects—objects, individuals, and locations—and articulate them with words. This pre-training phase lasts about 10 hours and necessitates four A100 (80GB) GPUs. The outputs generated during this stage are created by a vision transformer that processes the given image.
Nevertheless, the first phase of pre-training might yield outputs that are somewhat disjointed, characterized by repetitive phrases, incomplete sentences, or off-topic content. To rectify this, MiniGPT-4 undergoes a second training phase using a smaller yet high-quality dataset of image-text pairings to refine the model's text descriptions for greater accuracy and fluency.
From crafting website designs to resolving challenges shown in images, MiniGPT-4 marks a significant leap forward in the AI landscape, and this is merely the beginning.
Read more:
Disclaimer
uk uz , please remember that the details provided on this page are not designed as legal, tax, financial, or investment recommendations. It's essential to invest only what you can afford to lose and seek professional financial guidance if uncertain. For additional information, refer to the issuer or advertiser's terms and conditions, as well as the support pages. MetaversePost is dedicated to delivering precise and impartial reporting, but keep in mind that market situations can shift without prior notice.