


LLM Programs: A New Journey Towards Tailoring Neural Models for Challenging Scenarios
In Brief
The authors introduce LLM Programs as a fresh approach, viewed as an evolution of in-context learning methodologies.
The essence of addressing a challenge through the LLM Program lies in breaking the solution into a series of more manageable steps.
LLM customization largely centers on two aspects: the fine-tuning of pre-existing models—known as additional training—and the application of in-context learning. Engaging in fine-tuning typically demands notable computational power, extensive data gathering, and an appropriate infrastructure to host these specialized models. Conversely, in-context learning requires the careful crafting of prompts supplemented by problem-solving examples, such as the Chain-of-Thought (CoT) technique. Nevertheless, difficulties emerge, including constraints on the text size inputted into the model, and in scenarios where multi-step prompts coexist, there can be overlaps that impede clarity, causing the model to lose focus on the task. The authors present a different approach called... LLM Programs ...which reflects an advanced form of in-context learning.

| Recommended: Prompt Engineering Ultimate Guide 2023 |
Integrating LLM into conventional programming setups (for instance, via Python) allows for external code management, which maintains the model state incrementally. This method offers several advantages: programming languages are designed to accommodate these functions, it increases the available contextual scope, and it ensures orderly processing where steps don't interfere with each other. Decomposing complex problems into simpler sequential tasks showcases a noteworthy shift from historic strategies that relied on external tools—such as calculators or... programming language ...for state management. This method proves advantageous by facilitating the description of intricate tasks, which ultimately eases the processes of testing, debugging, and quality assessment. code interpreters Additionally, this approach significantly reduces step interference, thereby streamlining interactions with the LLM. It’s worth noting that question-answering systems have existed for years and were not solely developed alongside LLMs. So, how does the current methodology tackle the question-answering challenge?
Simply relying on a static model for potential answers isn't sustainable; it can quickly become outdated and won’t keep pace with new product introductions. Continuous retraining for every model update is neither practical nor economical. A more common approach involves indexing website content into databases, often employing vectorization techniques. When users query certain information, relevant documents are retrieved and provided for context to the LLM.
Sites are updated frequently, so a frozen model This framework seamlessly addresses the challenges presented by the LLM Program. As an additional perk, it permits the execution of intricate multi-pass logic that would be too complex to fit entirely within a single context.
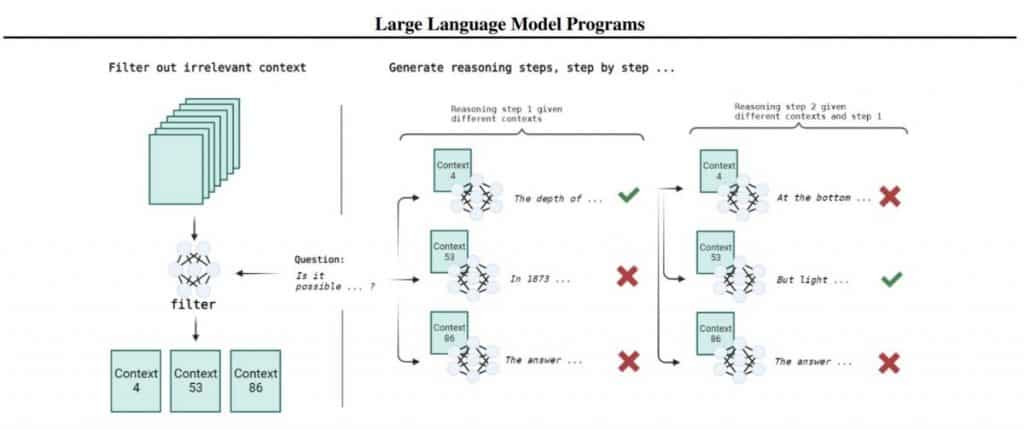
Considering binary classification dilemmas necessitates a multi-faceted reasoning approach. Take, for instance, the inquiry, 'Can sunlight reach the deepest parts of the Black Sea?' To deduce an answer, one must determine both the sea's maximum depth (2 kilometers) and how far light penetrates water (1 kilometer), leading to a conclusion. Let's examine another illustrative query: 'Did Aristotle use a laptop?' This question is less straightforward than 'Was Aristotle alive when the laptop was invented?' as it doesn't adhere to a clear sequence of reasoning steps. The dataset encompasses only those questions with implicit reasoning pathways. Out of 2,780 questions, merely 918 include paragraphs with supporting evidence for each step of reasoning. The current work remains confined to this subset; otherwise, we must depend on the LLM's ability to retain facts acquired during pretraining. becomes possible The OPT-175B LLM lacks proficiency in following instructions since it wasn't fine-tuned for instructional compliance or conversational purposes. To address the question-answering challenge grounded in evidence, the process is divided into a filtering stage followed by a tree search stage.
Tested on the StrategyQA dataset During the filtering stage, upon receiving a question, developers sift through paragraphs to identify the most applicable ones. For instance, using a few-shot prompt, we request the LLM to determine (yes/no) whether an individual paragraph pertains to the posed question. Trials conducted on a 300-question subset of StrategyQA paired each query with relevant or irrelevant paragraphs at a ratio of 50/50. Results indicate that both OPT-175B and text-davinci-002 perform...
...worse than a random baseline, achieving around 56%. The more sophisticated...
Given the deficiencies in this method, an alternative was devised, integrating the average negative log-likelihood (NLL) of the question in conjunction with the preceding paragraph, leading to a ranking of the results. Evaluated against a dataset where 100 paragraphs corresponded to each query and only one was relevant (meaning random guessing yields a 1% hit rate), we achieved top-1 accuracy at 79% and top-5 at 93%. For this evaluation, model access is typically required, which may not always be available via the API. much higher quality Subsequently, we enter the output chain construction phase, navigating through a tree where the question is positioned at the root level, followed by numerous paragraphs representing potential evidence that could provide context for generating the subsequent step. Each tree path corresponds to a prospective output chain. Due to the impracticality of evaluating every possible chain, we rank all available paths and expand the highest-scoring ones. This resembles a type of beam search strategy. The process continues until a response is generated or the maximum permitted steps are reached. 11B Tk-Instruct is not much better at 61.6%.
Crucial to this methodology are the two ranking strategies put to the test for the tree search step. The primary strategy assesses the average NLL across the entire chain, while the secondary strategy examines the average difference in NLL when a paragraph (P) is included versus when it’s not, as well as the question (Q). On the 918 questions from StrategyQA, this tactic markedly elevates answer quality compared to the baseline employing CoT (60%); both searching methods yield around 66%, with the second option having a slightly higher delta. When verifiable facts are included, quality spikes to roughly 81%, representing the maximum achievable for OPT. Darklang appears to be venturing in a similar direction but through an alternative route.
5 Compelling Reasons to Choose AI-Driven Bing Over Google
8 Essential Facts You Should Be Aware of Regarding Large Language Models
The article is based on the Telegram post .
Read more about AI:
Disclaimer
In line with the Trust Project guidelines Jupiter DAO Reveals ‘Next Two Years: DAO Resolution’ Proposal Aiming for Progressive Independence and Substantial Funding




