


The recent disclosures about GPT-4 shed light on both its impressive scale and its advanced architecture.
In Brief
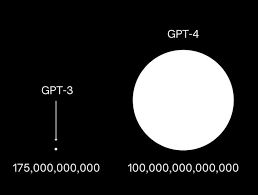
The buzz created by the information leak about GPT-4 has electrified the AI community. While it is reported to boast over ten times the number of parameters compared to GPT-3, the latest model is believed to feature around 1.8 trillion parameters spread out over 120 layers.
OpenAI has opted for a mixture of experts (MoE) approach in the design of GPT-4, featuring 16 experts where each operates with around 111 billion parameters within multi-layer perceptrons (MLP). With an efficient inference mechanism utilizing about 280 billion parameters and harnessing 560 TFLOPs per forward pass, this showcases OpenAI's dedication toward maximizing both efficiency and cost-effectiveness. The model has been trained on a staggering dataset consisting of 13 trillion tokens, fine-tuning from 8k to 32k.
By integrating parallel processing techniques, OpenAI was able to maximize the capabilities of their A100 GPUs for GPT-4. This involved both 8-way tensor parallelism and 15-way pipeline parallelism. The training was a demanding process, utilizing vast resources and costing between $32 million and $63 million.
Though the inference expense of GPT-4 is roughly three times higher than that of its predecessor, it does include features like multi-query attention, continuous batching, and speculative decoding. The system's inference operates on a combined array of 128 GPUs located in various data centers.
Recent leaks regarding GPT-4 have made significant waves in the AI field. Reports from an unnamed source have unveiled the astonishing abilities and unparalleled scale of this revolutionary model. Let’s dive deep into the details to uncover what truly sets GPT-4 apart as a technological wonder.

- GPT-4’s Massive Parameters Count
- Mixture of Experts Model (MoE)
- Simplified MoE Routing Algorithm
- Efficient Inference
- Extensive Training Dataset
- Improvement through specialized fine-tuning techniques from 8K to 32K
- Scaling with GPUs via Parallelism
- Challenges in training costs and resource utilization
- Tradeoffs in Mixture of Experts
- Inference Cost
- Multi-Query Attention
- Continuous Batching
- Vision Multi-Modal
- Speculative Decoding
- Inference Architecture
- Dataset Size and Composition
- Rumours and Speculations
- The Reporter’s Opinion
- The intrigue surrounding GPT-4's extensive knowledge base
- The Versatility of GPT-4
GPT-4’s Massive Parameters Count
Among the most notable insights from the leak is the extraordinary scale of GPT-4. With more than tenfold the parameters of the earlier GPT-3, this model is said to encompass an astonishing 1.8 trillion parameters spread across 120 layers, representing a massive leap in potential capabilities and innovations. trillion parameters To keep costs manageable while achieving stellar performance, OpenAI adopted a mixture of experts (MoE) model for GPT-4. By integrating 16 experts, each consisting of roughly 111 billion parameters for MLP, they optimized resource usage effectively. Remarkably, during each forward pass, only two experts engage, reducing computational burden without sacrificing output quality. Such an innovative approach reflects OpenAI's commitment to being both efficient and cost-effective in their designs. GPT-4’s enhanced capabilities The detailed leak about GPT-4's architecture presents a thorough and insightful exploration of the reasoning behind its strategies and the resulting implications, crafted by
Mixture of Experts Model (MoE)
A non-paywalled summary can be accessed here:
While GPT-4 generally harnesses advanced routing algorithms to determine expert utilization for token processing, the current model reportedly employs a more straightforward routing algorithm. Although simpler, this method effectively manages the selection; approximately 55 billion shared parameters enhance attention mechanisms for the optimal distribution of tokens among designated experts. @dylan522p : https://t.co/eHE7VlGY5V
— Jan P. Harries (@jphme) July 11, 2023
The inference procedure of GPT-4 serves as a testament to its computational efficiency and power. Generating a single token in each forward pass typically requires around 280 billion parameters and 560 TFLOPs, a stark contrast considering the overall scale of GPT-4, which boasts 1.8 trillion parameters and delivers a staggering 3,700 TFLOPs per forward pass in a fully dense setup. This resource-conscious strategy highlights OpenAI's pursuit of top-tier performance while avoiding unnecessary computational demands. https://t.co/rLxw5s9ZDt
Simplified MoE Routing Algorithm
Trained on an enormous dataset equating to roughly 13 trillion tokens, GPT-4 benefits from a diverse range of text inputs. It's crucial to note that these tokens encompass both unique tokens and those representing epoch indicators. This dataset includes two epochs for textual data and four for code, utilising millions of rows of finely-tuned instructional data gathered from ScaleAI and internal sources to enhance model performance.
Efficient Inference
During the pre-training for GPT-4, an 8k context length was initially employed, followed by a fine-tuning phase leading to the 32k version. This evolution builds upon its initial training and refines the model for specific functional applications.
Extensive Training Dataset
OpenAI fully exploited the capabilities of their A100 GPUs during GPT-4's development through parallelism. Utilizing 8-way tensor parallelism maximizes the parallel processing potential, aligned with NVLink limits. Additionally, 15-way pipeline parallelism has been incorporated to heighten overall performance. While techniques, such as ZeRo Stage 1, may have been part of the methodology, precise details remain undisclosed. training process The development of GPT-4 was an extensive undertaking that demanded significant resources. OpenAI utilized approximately 25,000 A100 GPUs over a timeframe extending from 90 to 100 days, operating at an average utilization rate between 32% and 36%. The challenging nature of the training process led to numerous failures, requiring regular returns to previous checkpoints. If calculated at $1 for every A100 GPU hour, the total expense for this particular run would approximate $63 million.
Improvement through specialized fine-tuning techniques from 8K to 32K
Adopting a mixture of experts model carries certain trade-offs. For GPT-4, OpenAI decided on 16 experts rather than expanding the number, reflecting an equilibrium between optimizing loss results and ensuring adaptability across varied tasks. Too many experts can complicate task generalization and convergence, reinforcing OpenAI's strategy of careful selection while committing to reliable and robust operational performance.
Scaling with GPUs via Parallelism
When compared with the 175 billion parameter Davinci model, GPT-4’s inference cost is about three times as high. This variation arises from multiple factors like the larger hardware clusters necessary for GPT-4 and its comparatively lower utilization rates during the inference stage. Estimates indicate around $0.0049 for every 1,000 tokens when using 128 A100 GPUs and $0.0021 when utilizing 128 H100 GPUs while inferring GPT-4 with an 8k context length. Such metrics assume optimal usage and substantial batch sizes, which are key factors for effective cost management.
Challenges in training costs and resource utilization
OpenAI also utilizes multi-query attention (MQA) within GPT-4—a common technique in the industry. By incorporating MQA, the system only requires a single head, drastically cutting down the memory needs for the key-value cache (KV cache). However, it's important to mention that the 32k batch version of GPT-4 cannot operate on 40GB A100 GPUs, and the 8k is limited by its maximum batch capacity. training costs To balance latency and inference expenses efficiently, OpenAI employs variable batch sizes alongside continuous batching in GPT-4. This flexible process optimizes resource utilization and diminishes computational overhead.
Tradeoffs in Mixture of Experts
introduces a dedicated vision encoder in addition to the text encoder, which features cross-attention between both modules. This alignment, reminiscent of Flamingo, adds further parameters to the already substantial 1.8 trillion parameter tally of GPT-4. The vision encoder is fine-tuned separately using about 2 trillion tokens after the pre-training phase focused solely on text, which equips the model to interpret web pages, transcribe imagery, and analyze videos—essential skills in today’s multimedia-centric world. caution in expert An intriguing element of GPT-4's inference approach might involve speculative decoding. This technique uses a smaller, expedited model to generate several token predictions ahead of time, which are then consolidated into a larger encompassing model for processing. If these initial predictions align with outcomes from the larger model, multiple tokens can be processed collectively. However, if they diverge, the predicted batch is eliminated, with inference continuing only with the larger model. This strategy seeks to streamline decoding while potentially endorsing lower-probability sequences, although such speculation has not yet been confirmed.
Inference Cost
The inference process for GPT-4 is conducted on a cluster comprising 128 GPUs, strategically distributed across various data centers. This infrastructure is designed incorporating 8-way tensor parallelism and 16-way pipeline parallelism, aimed at maximizing efficient computation. Each node integrates 8 GPUs, managing approximately 130 billion parameters, and with a configuration of 120 layers, GPT-4 can be accommodated within 15 nodes, potentially with fewer layers in the first one to handle embeddings efficiently. Such meticulous architectural choices underscore OpenAI's commitment to pushing the limits of computational efficiency.
Multi-Query Attention
GPT-4 was meticulously trained using an astounding 13 trillion tokens, endowing it with a vast repository of text for its learning phase. However, it’s essential to consider that the known datasets utilized during training do not fully account for all tokens. While sources like CommonCrawl and RefinedWeb contribute significantly to the training corpus,
Continuous Batching
Revealing Insights into GPT-4's Enormous Scale and Cutting-Edge Design - Metaverse Post
Vision Multi-Modal
GPT-4 The recent exposure of information about GPT-4 has created quite a stir in the AI sector. Sourced from an unnamed informant, autonomous agents Revealing Insights into GPT-4's Enormous Scale and Cutting-Edge Design
Speculative Decoding
Unveiling the Significant Size and Architecture of GPT-4 model FTC's Attempt to Block the Microsoft-Activision Merger Fails model’s predictions Published: July 11, 2023, at 7:19 am | Updated: July 11, 2023, at 7:23 am
Inference Architecture
To enhance your experience in your local language, we sometimes use an automated translation tool. Keep in mind these translations may not always be accurate, so please proceed with caution.
Dataset Size and Composition
The details that have leaked about GPT-4 have generated significant excitement within the AI community. With a parameter count that vastly surpasses GPT-3 by over tenfold, GPT-4 is believed to encapsulate around 1.8 trillion parameters spread across 120 distinct layers. training data OpenAI has adopted a Mixture of Experts (MoE) architecture for this model, featuring 16 experts, each carrying around 111 billion parameters for multi-layer perceptrons (MLP). It operates with an optimized inference structure that efficiently uses 280 billion parameters and achieves 560 TFLOPs per token generation, showcasing OpenAI's focus on maximizing both performance and cost efficiency. Moreover, the training corpus includes an enormous 13 trillion tokens, fine-tuned from an initial range of 8k to 32k.
Rumours and Speculations
To fully exploit the capabilities of their A100 GPUs, OpenAI took advantage of parallel processing in GPT-4 by implementing 8-way tensor parallelism along with 15-way pipeline parallelism. The training phase was extensive, requiring substantial resources with costs estimated between $32 million and $63 million.
The Reporter’s Opinion
The inference expenses for GPT-4 approximately triple those of its predecessor, although it integrates advanced techniques such as multi-query attention, continuous batching, and speculative decoding. The inference framework operates on a robust array of 128 GPUs spread across various data centers.
The intrigue surrounding GPT-4's extensive knowledge base
The recent details that have come to light regarding GPT-4
The Versatility of GPT-4
have caused quite a sensation in the AI domain. The leaked intelligence, sourced from an unidentified provider, offers a window into the remarkable capabilities and unparalleled scope of this pioneering AI model. In the following sections, we will dissect the relevant data and highlight the critical features that contribute to GPT-4 being a genuine breakthrough in technology.
Read more about AI:
Disclaimer
In line with the Trust Project guidelines To balance costs while delivering outstanding performance, OpenAI has embedded a mixture of experts (MoE) model into GPT-4. By utilizing 16 experts in the framework, each containing roughly 111 billion parameters for multi-layer perceptrons (MLP), OpenAI optimizes its resource usage. Notably, only two experts are active during each forward pass, ensuring lower computational demands without sacrificing quality. This strategy demonstrates OpenAI's dedication to achieving maximum efficiency and cost-effectiveness.




