


Introducing GLIGEN, the innovative text-to-image generation model equipped with bounding box capabilities.
In Brief
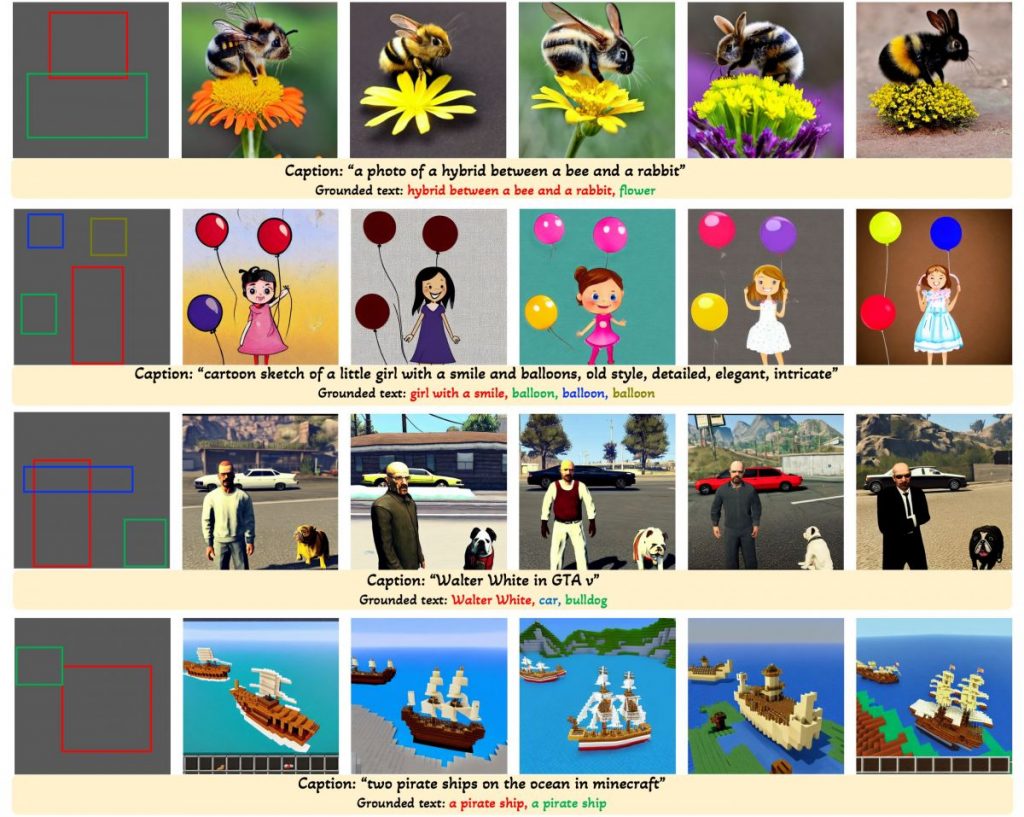
GLIGEN, short for Grounded-Language-to-Image Generation, is an exciting new method that expands upon and enhances the capabilities of existing pre-trained diffusion models.
By incorporating both caption and bounding box input conditions, the GLIGEN model is capable of generating text-to-image outputs in a rich open-world context.
Drawing from knowledge of a pre-trained text-to-image model, GLIGEN is proficient in generating diverse objects that can be placed in specific contexts and styling.
Another unique feature of GLIGEN is its ability to incorporate human keypoints during the text-to-image generation process.
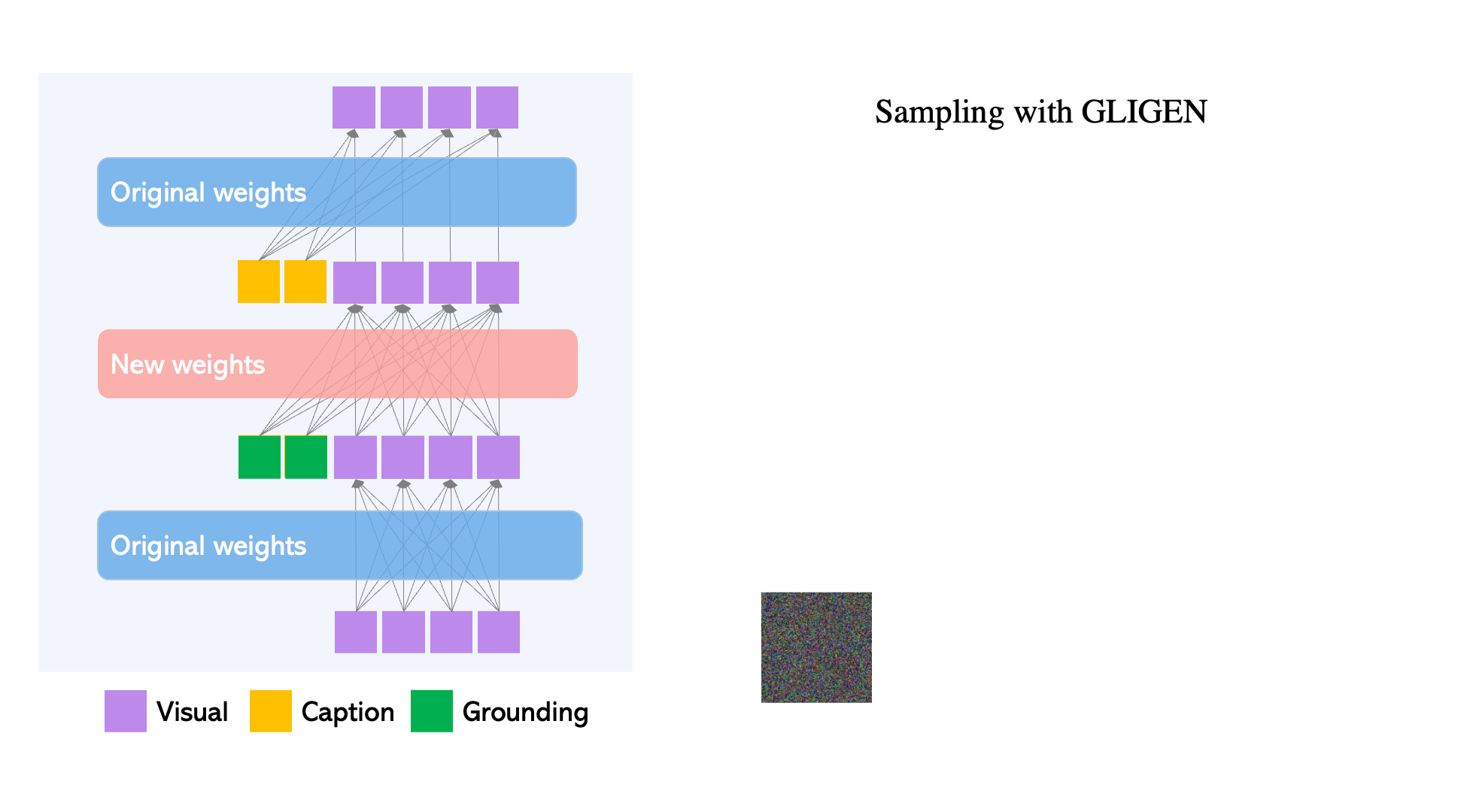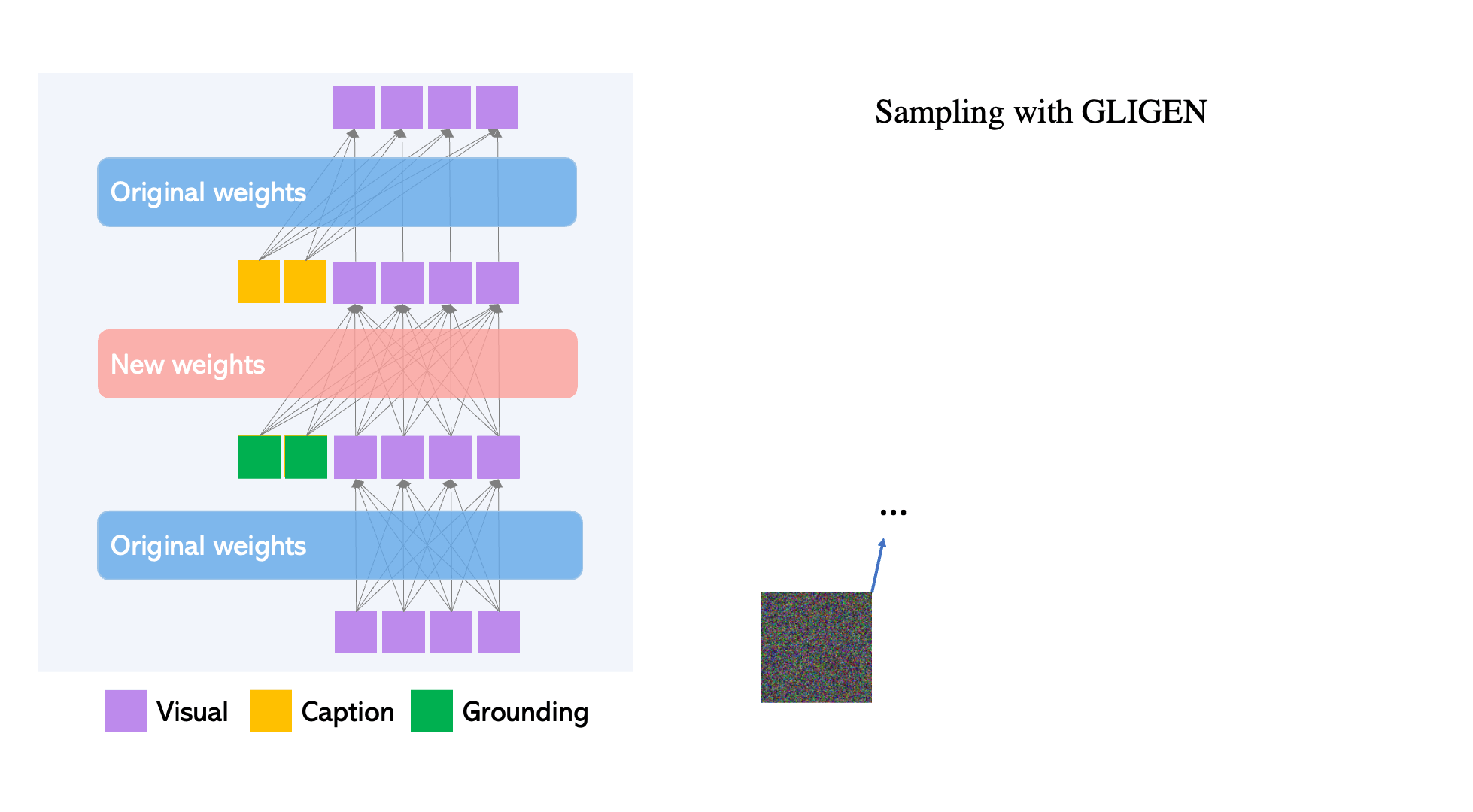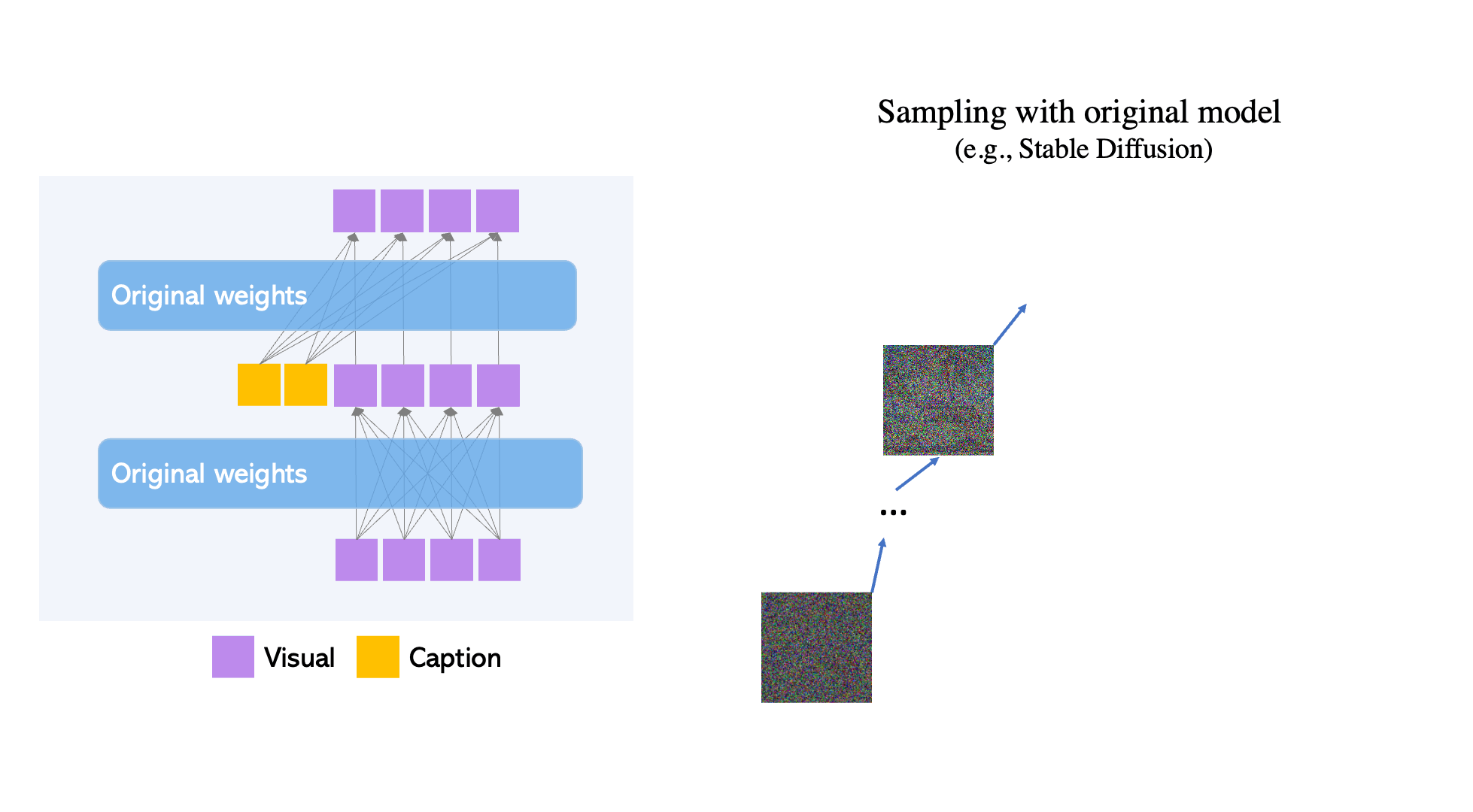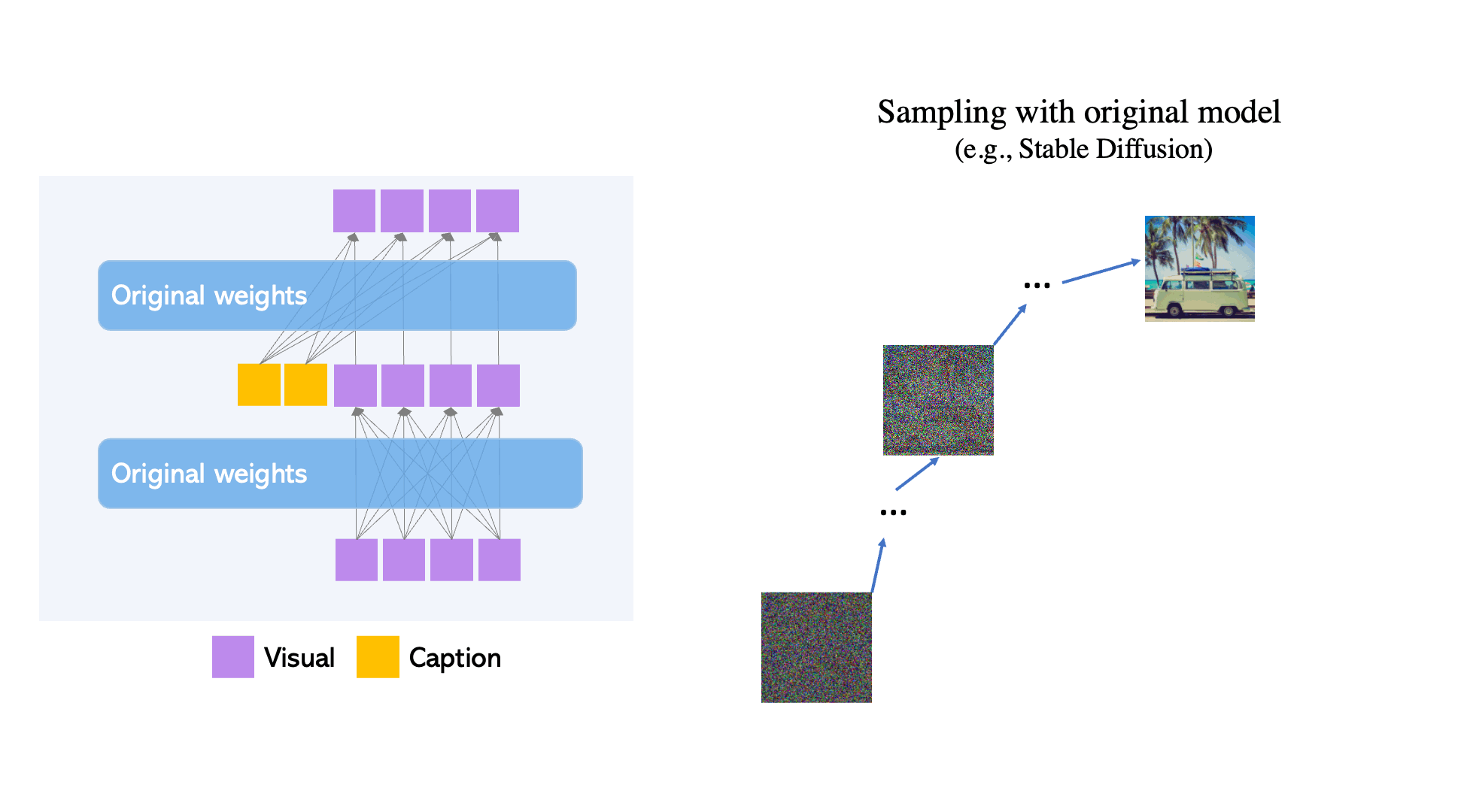
Though large-scale text-to-image diffusion technology has advanced significantly, the predominant technique of relying solely on text inputs often restricts the level of control available. GLIGEN The Grounded-Language-to-Image Generation technique enhances already established pre-trained models by allowing them to respond to grounding inputs.

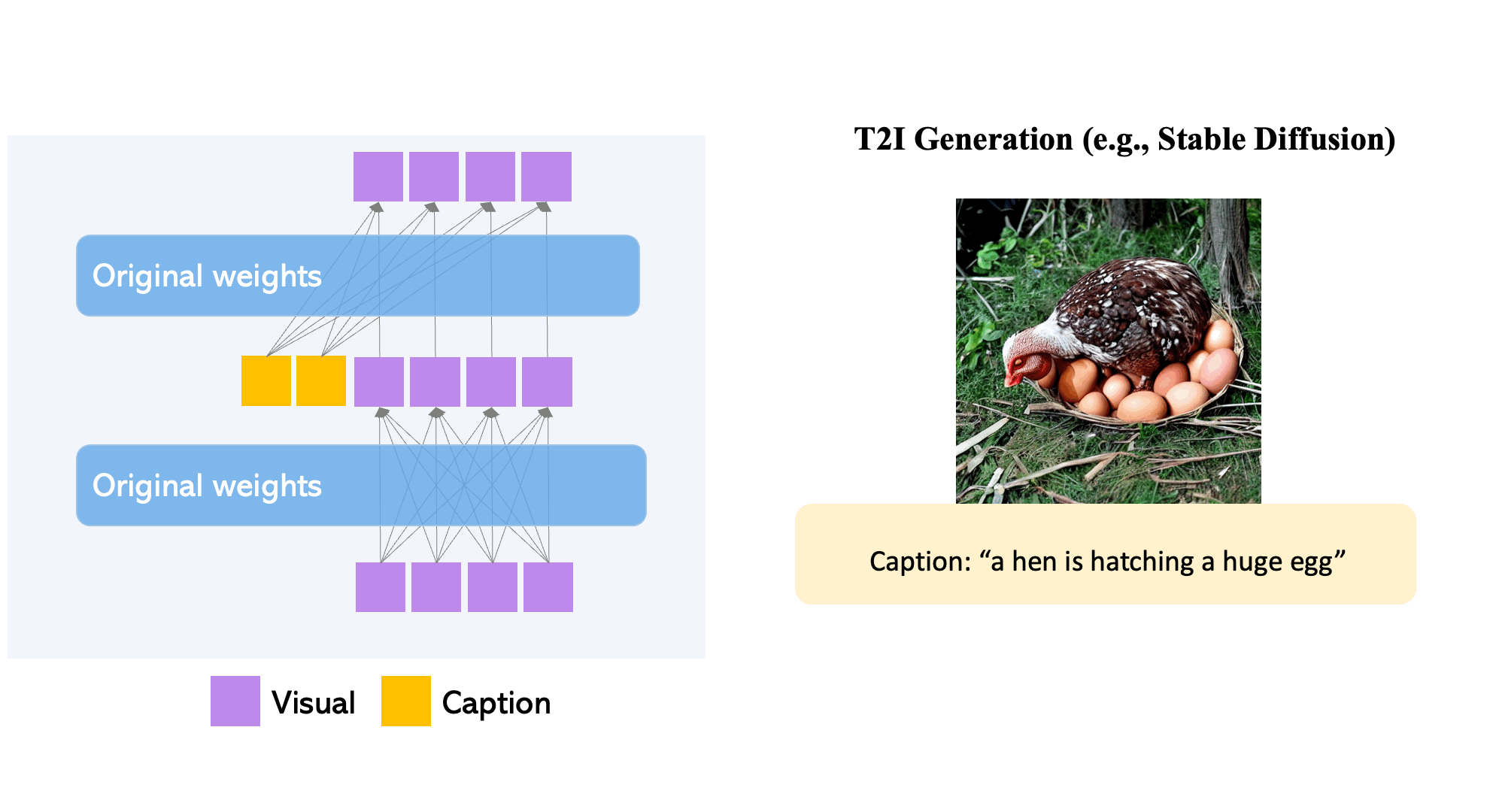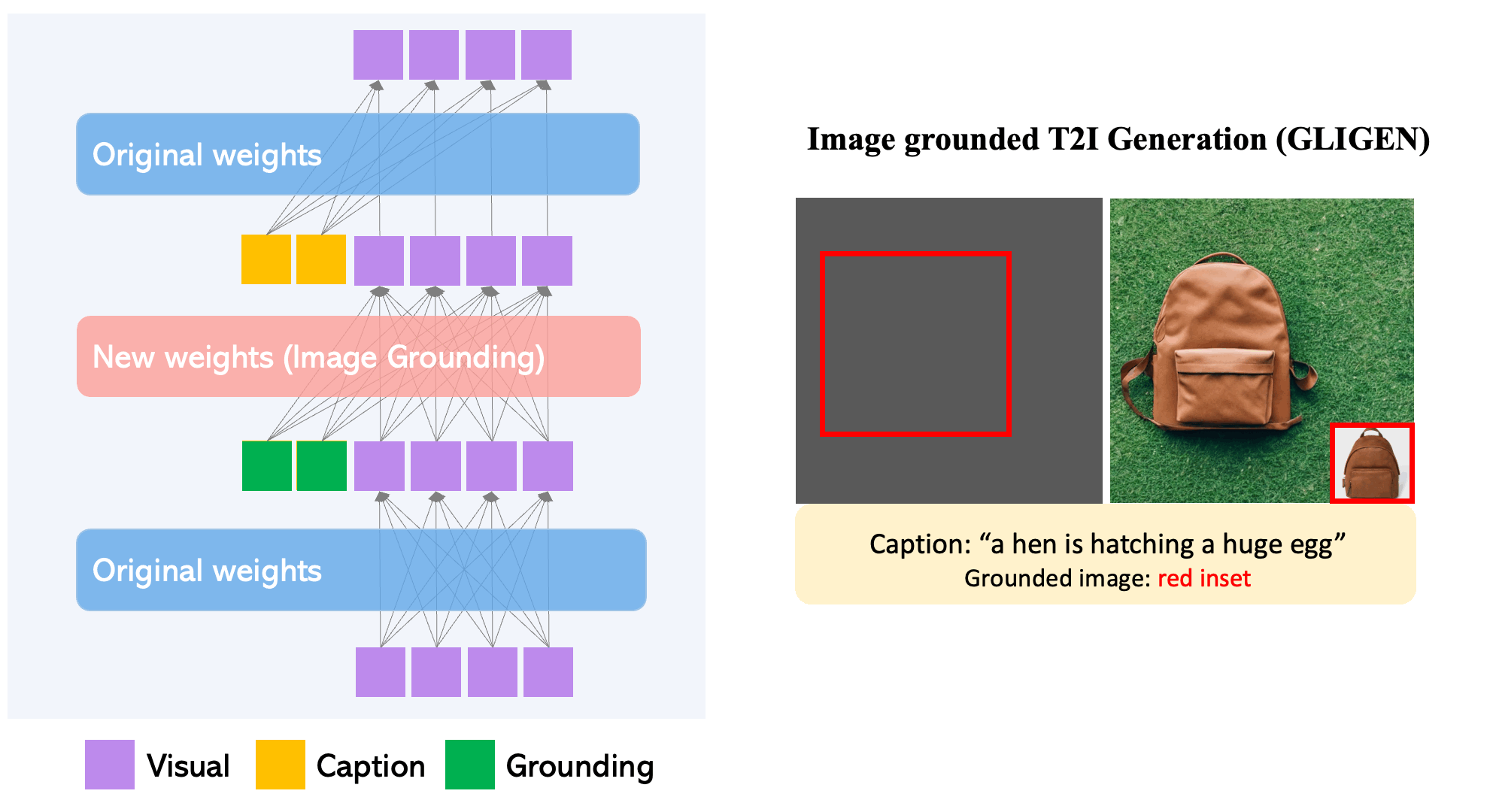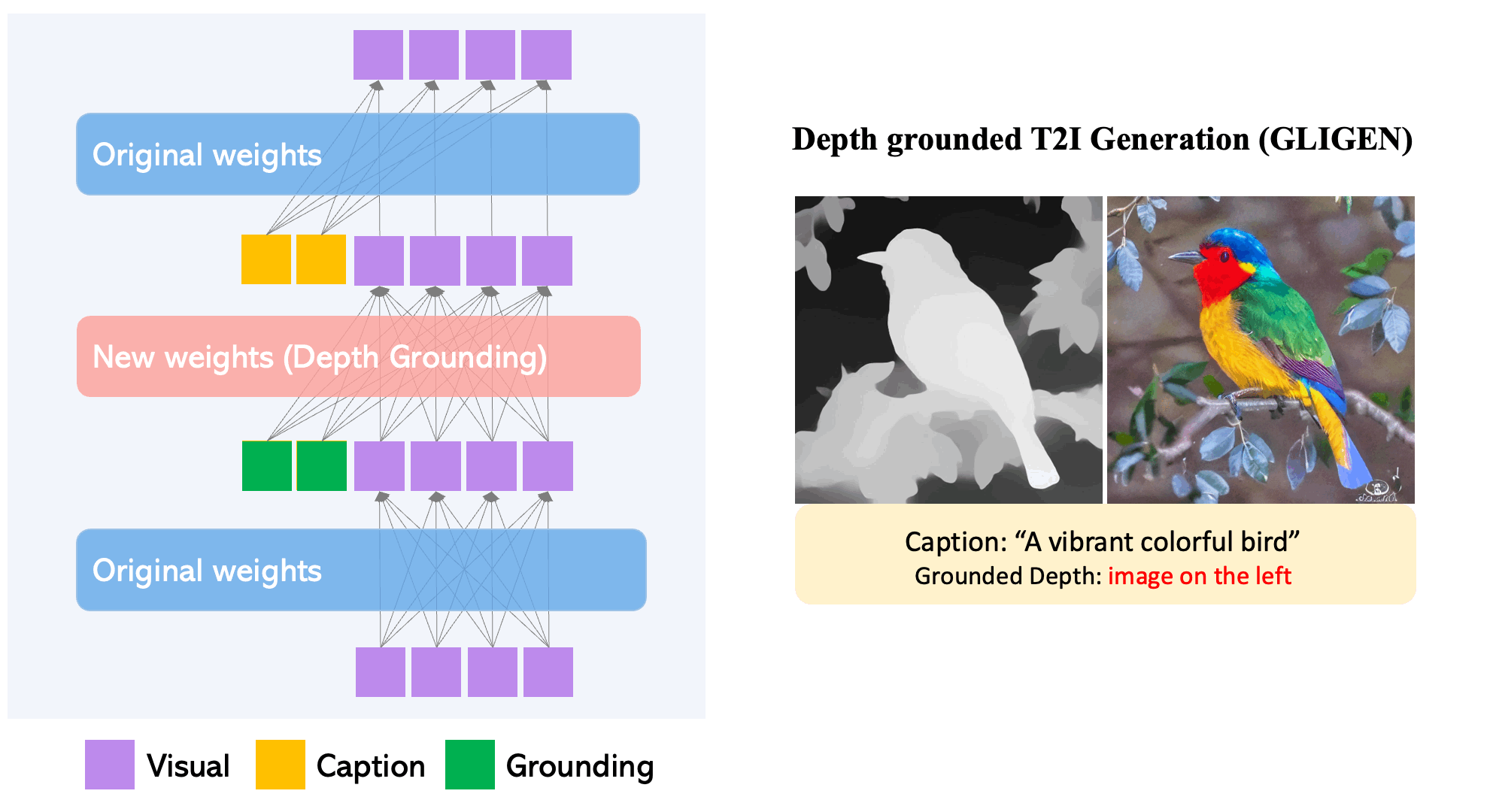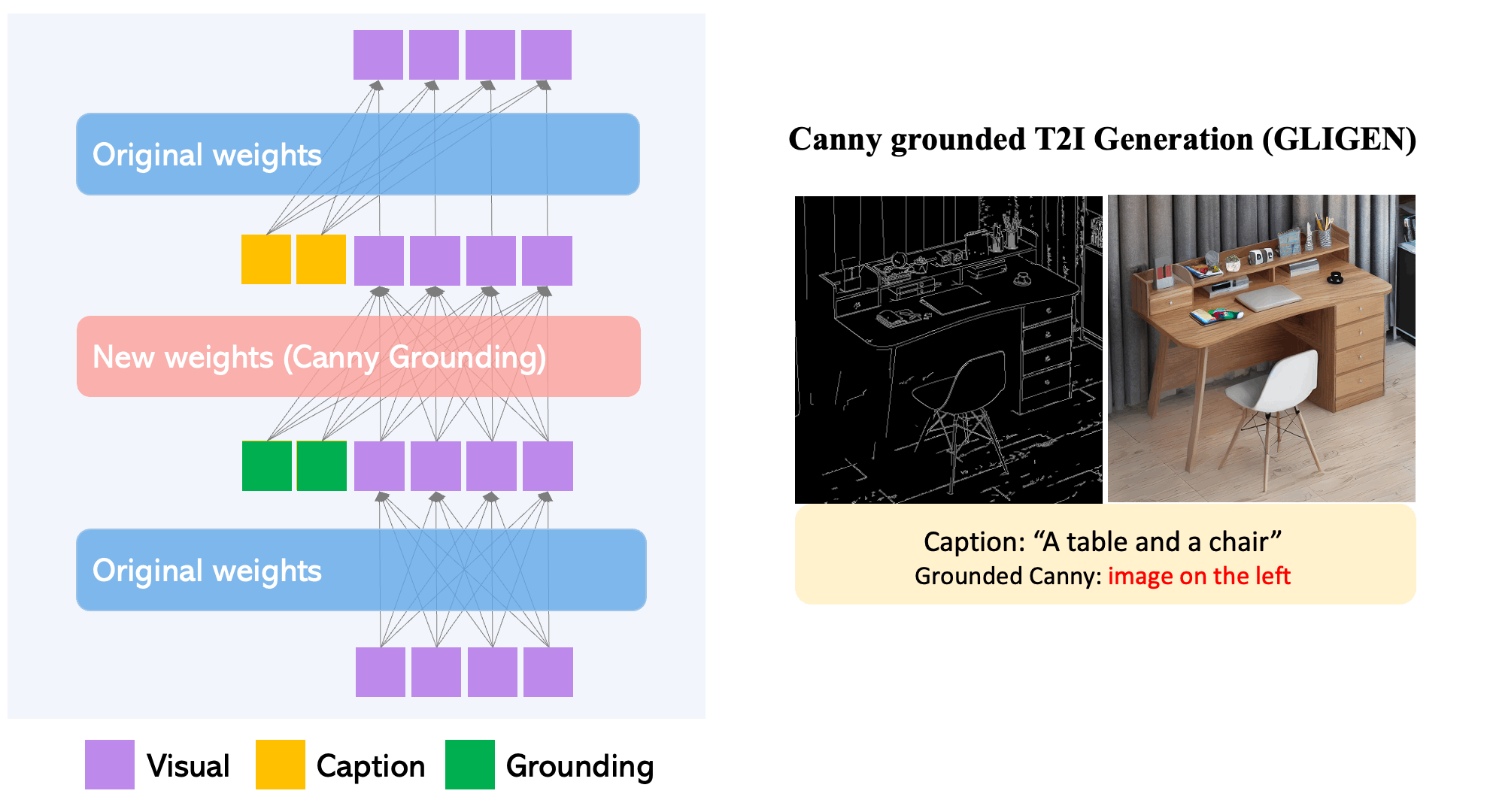
To ensure the pre-trained model retains its extensive concept knowledge, all original weights are preserved, while new, trainable layers incorporate the grounding data through a controlled procedure. With caption and bounding box as inputs, GLIGEN creates grounded text-to-image outputs that can generalize effectively to new spatial configurations and ideas.
Check out the demo here.

- Each transformer block introduces a new trainable Gated Self-Attention layer, designed specifically to take in additional grounding information. diffusion models When it comes to grounding tokens, they contain dual types of information: semantic details about the item being grounded (which could be from text or images) and positional information regarding space (provided as bounding boxes or key points).
- VToonify: a real-time AI solution crafted to produce artistic portrait videos.
- The newly integrated modulated layers are continuously trained using extensive grounding data (image-text-box). This approach proves to be more cost-efficient compared to other methods of applying a pre-trained diffusion model, like full-model finetuning. Much like a Lego, these diverse trained layers can be easily swapped in and out, introducing various new functionalities.



Read more about AI:
Disclaimer
In line with the Trust Project guidelines In order for DeFAI to realize its full potential, it must address the challenges of cross-chain compatibility.